Du solltest besser nicht das Original verändern, sondern das Ergebnis mit den Veränderungen extra speichern und zum Austausch wieder auf das Original zurückgreifen.
Beiträge von BugFix
-
-

Wenn ich mir $sText ausgeben lasse ist es halt manchmal ein leerer String
Ja, ich war der (irrigen) Meinung, wenn ich die Listbox befüllt habe, ist doch da auf jeden Fall Inhalt. Der Inhalt, der in der Callbackfunktion relevant ist, entsteht ja erst beim Zeichnen desselben. Somit ist beim ersten Zeichnen der Wert von _GUICtrlComboBox_GetLBText noch leer und führt zum Crash.
Ich habe die Callbackfunktion jetzt dahingehend angepasst, dass sie bei leerem Text wieder verlassen wird.
AutoIt
Alles anzeigenFunc _WM_DRAWITEM($hWnd, $iMsg, $iwParam, $ilParam) Local Const $tagDRAWITEMSTRUCT = 'uint CtlType;' & 'uint CtlID;' & 'uint itemID;' & 'uint itemAction;' & _ 'uint itemState;' & 'hwnd hwndItem;' & 'hwnd hDC;' & $tagRECT & ';ulong_ptr itemData;' Local $tDIS = DllStructCreate($tagDRAWITEMSTRUCT, $ilParam) Local $clrForeground = 0x000000, $clrBackground = 0xFFFFFF, $sText Local Static $clrPrev = $clrForeground $clrForeground = $clrPrev Local $iCtlType = $tDIS.CtlType Local $iCtlID = $tDIS.CtlID Local $iItemID = $tDIS.itemID Local $iItemAction = $tDIS.itemAction Local $iItemState = $tDIS.itemState Local $hWndItem = $tDIS.hwndItem Local $hDC = $tDIS.hDC Local $tRect = DllStructCreate($tagRECT) If $iCtlType = $ODT_COMBOBOX And $iCtlID = $cCombo Then For $i = 1 To 4 DllStructSetData($tRect, $i, DllStructGetData($tDIS, $i+7)) Next _GUICtrlComboBox_GetLBText($hWndItem, $iItemID, $sText) ; ################################################ If $sText = '' Then Return $GUI_RUNDEFMSG ; ################################################ Switch $iItemAction Case $ODA_DRAWENTIRE $clrForeground = 0x000000 If BitAND($iItemState, $ODS_SELECTED) Then $clrBackground = _WinAPI_SetBkColor($hDC, 0xD8D8D8) Else $clrBackground = _WinAPI_SetBkColor($hDC, 0xFFFFFF) EndIf If $mUnit[$sText]['access'] = 0 Then $clrForeground = 0x0000FF $clrPrev = _WinAPI_SetTextColor($hDC, $clrForeground) _WinAPI_DrawText($hDC, $sText, $tRect, $DT_LEFT) _WinAPI_SetTextColor($hDC, $clrForeground) _WinAPI_SetBkColor($hDC, $clrBackground) EndSwitch EndIf Return $GUI_RUNDEFMSG EndFunc -
Ich habe die Problematik mal auf ein mimimales Skript runtergebrochen.
Im Original lese ich Daten aus einer INI in eine Map, habe ich hier nachgestellt.
Diese Daten sollen abhängig von dem Wert in 'access' (0/1) in rot oder Schwarz in der Combobox gelistet werden. Das funktioniert auch grundlegend.
Versuche ich jedoch innerhalb der WM_DRAWITEM-Funktion aus der Map den Wert für 'access' abzufragen, um entsprechend einzufärben, bekomme ich einen Fehler:Code==> Array variable has incorrect number of subscripts or subscript dimension range exceeded.: If $mUnit[GUICtrlRead($cCombo)]['access'] = 0 Then $clrForeground = 0x0000FF If $mUnit[GUICtrlRead($cCombo)]^ ERRORWie aber im Skript sichtbar ist, lasse ich zur Kontrolle die gesamte Map vorab in die Konsole ausgeben - problemlos.
Eigentlich könnte ich statt GUICtrlRead($cCombo) auf das funktionsintern gelesene $sText zugreifen. Hatte das aber mal testweise geändert, um es als Fehlerquelle auszuschließen.Vielleicht hat ja schonmal jemand das Problem gehabt.
In Zeilen #90 / #91 mal die Kommentierung tauschen, um den Effekt zu sehen.
AutoIt
Alles anzeigen#include <GUIComboBox.au3> #include <GUIConstantsEx.au3> #include <WindowsConstants.au3> #include <WinAPI.au3> Global Const $ODT_COMBOBOX = 3 Global Const $ODA_DRAWENTIRE = 1 Global Const $ODA_SELECT = 2 Global Const $ODS_SELECTED = 1 Global $hGUI Global $cCombo, $inPath Global $sStr = '' $hGUI = GUICreate('Test', 600, 400) $cCombo = GUICtrlCreateCombo('', 100, 20, 300, 300, BitOR($WS_CHILD, $CBS_OWNERDRAWFIXED, $CBS_HASSTRINGS, $CBS_DROPDOWNLIST, $CBS_AUTOHSCROLL, $WS_VSCROLL)) $inPath = GUICtrlCreateInput('', 100, 50, 300, 20) Global $sPathRoot = 'D:\Units' Global $mUnit[] ; $m['Einheit']['path'] / $m['Einheit']['template'] / $m['Einheit']['access'] For $i = 1 To 15 Local $m[] $mUnit['Einheit_' & $i] = $m $mUnit['Einheit_' & $i]['path'] = $sPathRoot & '\Einheit_' & $i $mUnit['Einheit_' & $i]['template'] = 'Template_' & Random(1,100,1) $mUnit['Einheit_' & $i]['access'] = Random(0,1,1) Next For $key in MapKeys($mUnit) $sStr &= '|' & $key Next GUICtrlSetData($cCombo, $sStr) ; ============================= Testausgabe Inhalt Map: For $key in MapKeys($mUnit) ConsoleWrite($key & ': ' & $mUnit[$key]['path'] & ' | ' & $mUnit[$key]['template'] & ' | ' & $mUnit[$key]['access'] & @CRLF) Next ; ============================================= GUIRegisterMsg($WM_DRAWITEM, '_WM_DRAWITEM') GUISetState() While True Switch GUIGetMsg() Case -3 Exit Case $cCombo $sSel = GUICtrlRead($cCombo) GUICtrlSetData($inPath, $mUnit[$sSel]['path']) EndSwitch WEnd Func _WM_DRAWITEM($hWnd, $iMsg, $iwParam, $ilParam) Local Const $tagDRAWITEMSTRUCT = 'uint CtlType;' & 'uint CtlID;' & 'uint itemID;' & 'uint itemAction;' & _ 'uint itemState;' & 'hwnd hwndItem;' & 'hwnd hDC;' & $tagRECT & ';ulong_ptr itemData;' Local $tDIS = DllStructCreate($tagDRAWITEMSTRUCT, $ilParam) Local $clrForeground = 0x000000, $clrBackground = 0xFFFFFF, $sText Local Static $clrPrev = $clrForeground $clrForeground = $clrPrev Local $iCtlType = $tDIS.CtlType Local $iCtlID = $tDIS.CtlID Local $iItemID = $tDIS.itemID Local $iItemAction = $tDIS.itemAction Local $iItemState = $tDIS.itemState Local $hWndItem = $tDIS.hwndItem Local $hDC = $tDIS.hDC Local $tRect = DllStructCreate($tagRECT) If $iCtlType = $ODT_COMBOBOX And $iCtlID = $cCombo Then For $i = 1 To 4 DllStructSetData($tRect, $i, DllStructGetData($tDIS, $i+7)) Next _GUICtrlComboBox_GetLBText($hWndItem, $iItemID, $sText) Switch $iItemAction Case $ODA_DRAWENTIRE $clrForeground = 0x000000 If BitAND($iItemState, $ODS_SELECTED) Then $clrBackground = _WinAPI_SetBkColor($hDC, 0xD8D8D8) Else $clrBackground = _WinAPI_SetBkColor($hDC, 0xFFFFFF) EndIf ; ################################################################################################## ;~ If $mUnit[GUICtrlRead($cCombo)]['access'] = 0 Then $clrForeground = 0x0000FF If Random(0,1,1) = 0 Then $clrForeground = 0x0000FF ; ################################################################################################## $clrPrev = _WinAPI_SetTextColor($hDC, $clrForeground) _WinAPI_DrawText($hDC, $sText, $tRect, $DT_LEFT) _WinAPI_SetTextColor($hDC, $clrForeground) _WinAPI_SetBkColor($hDC, $clrBackground) EndSwitch EndIf Return $GUI_RUNDEFMSG EndFunc -

Iconcache löschen
Jo, Danke. Da sind wir inzwischen bei Win11, mit Hardwareanforderungen, die jedes Raumfahrtmodul übertreffen, aber sowas Sinnloses, wie ein Icon-Cache, der in Mikrosekunden befüllt ist, existiert immer noch.

-
Ich habe in einem Projektordner das verwendete Icon als "app.ico" gespeichert.
Jetzt wollte ich es mit einem anderen Icon ersetzen, im Screenshot "app_neu.ico".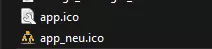
Also habe ich das neue Icon in den Ordner kopiert als "app.ico" - Überschreiben bestätigt. Und danach, zu meiner Überraschung, sah es so aus:

Nun habe ich das neu kopierte Icon, das immer noch aussieht, wie das alte mal umbenannt:


ABER, sowie ich es wieder zurück benenne, bekommt es die alte Ansicht.
Ich bin maximal verwirrt.
 Dachte mir noch, vielleicht gibt es ja irgendeinen Pufferspeicher für das Explorerfenster. Habe diesen also geschlossen, neu geöffnet und mich in das Verzeichnis durchgeklickt - unveränderte Situation.
Dachte mir noch, vielleicht gibt es ja irgendeinen Pufferspeicher für das Explorerfenster. Habe diesen also geschlossen, neu geöffnet und mich in das Verzeichnis durchgeklickt - unveränderte Situation.
EDIT:
Also es liegt doch am Pufferspeicher, der wird nur nicht geleert, wenn man den Explorer beendet. Aber beim Wechsel von Miniaturansicht zu Maximalansicht wird das korrekte Bild angezeigt. - Also ein reines Explorerproblem.
-

Ja, absoluten Respekt für deine Ausdauer.

Als ich vor 18 Jahren mit AutoIt anfing, habe ich anfangs nur für mich Vieles übersetzt. Für Anfänger ist es wirklich extrem wichtig eine Hilfe in der Muttersprache zu haben.
Später habe ich, wie so viele Andere hier auch, intensiv an deinem Übersetzungsprojekt mitgearbeitet. Wobei ich für mich dann feststellen konnte, dass mit steigender Anzahl an Übersetzungen und wachsenden Fähigkeiten, ich lieber mit der englischen Hilfe arbeite.
Aber nochmal Tweaky - dein Engagement ist bewundernswert.

-
Ich setze hier mal einen Schlusspunkt, ehe das hier noch irgendwie ausartet. Zumal der TE sich bisher nicht wieder gemeldet hat und das ursprüngliche Thema somit durch ist.
-

INI-Files die der Benutzer erstellt sollten immer unter dem Userprofilepfad befinden.
In einer Mehrbenutzerumgebung stimme ich dir zu. Aber ich schätze mal, dass mehr als 70% der privat genutzten PC nur von einem User genutzt werden. Ich persönlich kenne niemanden, bei dem auf dem Privat-PC mehrere User angelegt sind.
Aber natürlich kann jeder, der das Programm nutzen möchte, diese minimale Änderung einpflegen (Ändern einer Variablenzuweisung).
Nachtrag:
Wenn ich Software für andere erstelle, schreibe ich erst recht nicht in die AppData. Für den "Normaluser" ist dieser Bereich nicht sichtbar, es sei denn er gibt die Ordneradresse per Hand ein. Somit läuft man Gefahr, dass sich dort viel Datenmüll ansammelt.
Mehrbenutzerverwaltung lässt sich auch in einer INI ohne Probleme realisieren. Bekommt einfach jeder User seine Sektion.
-

Funktioniert das nur für Programme oder ev. auch für Ordnerpfade? Bzw könnte man die Pfade ev. in der *.ini hinterlegen?
In der Auswahl ist ein Filter für EXE Dateien, müsstest du also per Hand in die INI schreiben.
z.B.Bei Klick auf den Menüpunkt wird der Ordner im Dateiexplorer geöffnet. Wenn du die Einträge in der INI vornimmst, während das Menüprogramm läuft, musst du danach zumindest das Verwaltungsmenü Öffnen und Schließen, damit die Änderungen eingelesen werden. Icon hast du allerdings keines.
EDIT:
Wenn du die folgende geänderte Funktion ins Skript einfügst (ca. Zeile 270) wird bei nicht gefundenem Icon automatisch das Ordnersymbol verwendet.
AutoIt
Alles anzeigenFunc _GUICtrlCreateListViewImgItem($_sText, $_idLV, $_sPathImg, $_iOrdImg=-1) Switch $_sPathImg Case 'Verwalten' $_sPathImg = $SHELL32DLL $_iOrdImg = -322 Case 'Sleep' $_sPathImg = $SHELL32DLL $_iOrdImg = -212 Case 'Restart' $_sPathImg = $SHELL32DLL $_iOrdImg = -239 Case 'Shutdown' $_sPathImg = $SHELL32DLL $_iOrdImg = -216 EndSwitch GUICtrlCreateListViewItem(' ' & $_sText, $_idLV) If GuiCtrlSetImage(-1, $_sPathImg, $_iOrdImg) = 0 Then GuiCtrlSetImage(-1, $SHELL32DLL, -5) EndIf EndFunc -
In diesem Thread hatte ich die Problematik, Listview Einträge mit Icon untereinander anzuordnen.
Benötigt habe ich das hierfür - mein eigenes Favoritenmenü. Natürlich kann man das alles auch im Windows Startmenü anpinnen. Ich wollte jedoch ein Menü ausschließlich für meine Favoriten.Das Menü wird eingeblendet mit <Strg+Shift+M> und kann mit <Esc> ausgeblendet werden. Je nach Position der Taskbar wird auch das Menü positioniert, in Windows 11 ist das ja offiziell nur noch unten erlaubt.

Links-Klick auf einen Eintrag führt die hinterlegte Anwendung aus, Rechts-Klick zeigt einen Tooltipp mit dem Anwendungspfad.
Falls gewollt, kann man die Menüanwendung mit <Strg+Alt+M> beenden.Beim ersten Start wird eine INI Datei im Ordner der EXE erstellt, mit dem Namen der EXE. Beim ersten Aufruf des Menüs ist nur ein Eintrag zum Start der Verwaltungsoberfläche enthalten.
Die Nutzung der Verwaltungsoberfläche ist eigentlich selbsterklärend:
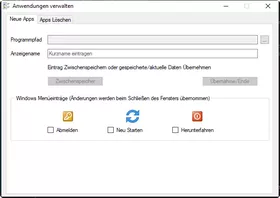
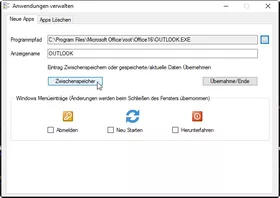
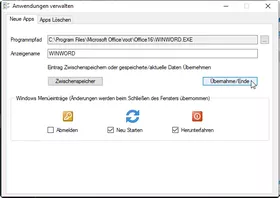
Als Alias wird automatisch der Programmname verwendet, ist aber frei editierbar. Die System-Events: Abmelden / Neustart / Herunterfahren können per Checkbox in das Menü übernommen werden.
Mit jedem Menüeintrag wird das Menü dynamisch angepasst. Die Icon der Anwendungen werden in das Menü übernommen.
Werden mehrere Anwendungen nacheinander durch Zwischenspeichern erfasst, wird beim Aufruf des Auswahlmenüs automatisch der zuletzt verwendete Pfad verwendet. Vermeidet lästiges Durchklicken.
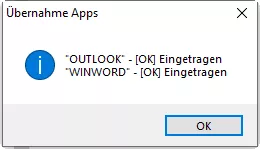 Die Änderungen sind sofort im Menü gültig:
Die Änderungen sind sofort im Menü gültig: 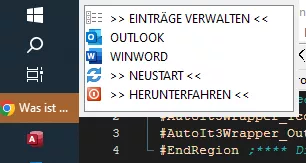
Die Apps lassen sich einfach durch Demarkieren der Checkbox wieder vom Menü entfernen.
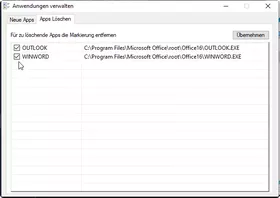 AutoIt: FavoritenMenu.au3
AutoIt: FavoritenMenu.au3
Alles anzeigen; TIME-STAMP 2025-02-17 14:16:12 #cs ==== Favoriten Menü ==== Dynamisch anpassbares Menü für App-Favoriten Kompilierte *.exe in eigenem Ordner speichern, dort wird dann die zugehörige INI-Datei erstellt. Einfügen in Autostart: • <Win+R> "shell:startup" (oder händisch öffnen: "C:\Users\USER\AppData\Roaming\Microsoft\Windows\Start Menu\Programs\Startup") • Link zur *.exe einfügen Einblenden Menü: <Ctrl+Shift+M> Ausblenden Menü: <Esc> (nur erforderlich, wenn kein Menüpunkt gewählt wird) Menüprogramm Beenden: <Ctrl+Alt+M> Links-Klick Menüeintrag: Ausführen der hinterlegten Anwendung Rechts-Klick Menüeintrag: Anzeige Anwendungspfad als Tooltipp #ce ==== #include <Array.au3> #include <ButtonConstants.au3> #include <EditConstants.au3> #include <GUIConstantsEx.au3> #include <GuiEdit.au3> #include <GuiListView.au3> #include <ListViewConstants.au3> #include <Misc.au3> #include <StaticConstants.au3> #include <StructureConstants.au3> #include <WindowsConstants.au3> If _Singleton(@ScriptName, 1) = 0 Then MsgBox(48+262144, @ScriptName, 'Eine Instanz dieses Programms ist bereits gestartet!') Exit EndIf ; Gui nicht mit ESC schließen Opt("GUICloseOnESC", 0) ; kein Traymenü anzeigen Opt("TrayMenuMode", 1) ; Trayicon verstecken Opt("TrayIconHide", 1) Global $INI = @ScriptDir & "\" & StringLeft(@ScriptName, StringInStr(@ScriptName, '.', 0, -1)) & "ini" If Not FileExists($INI) Then IniWrite($INI, 'remarks', 'Info', '[apps] "Alias=Anwendungspfad"') IniWrite($INI, 'winitem', 'logout', '0') IniWrite($INI, 'winitem', 'restart', '0') IniWrite($INI, 'winitem', 'shutdown', '0') EndIf Global $aApps[1][2] Global $SHELL32DLL = @WindowsDir & '\System32\SHELL32.dll' Global $PROGRAMFILES = StringLeft(@WindowsDir, 3) & "Program Files" ; Variablen Manage-Gui (für Hinzufügen/Entfernen von Apps) Global $hGuiNew, $hTab Global $tabNew, $inPath, $btSelect, $sSel, $inAlias, $btNext, $btEnd, $aBuffer[1][2] = [[Null]], $sRes, $sPathLast = $PROGRAMFILES Global $tabDel, $btDel, $LVDel, $hLVDel Global $icoLogout, $icoRestart , $icoShutdown, $cbLogout, $cbRestart, $cbShutdown _Manage_CreateGUI() ; Variablen Main-Gui (Menü) Global $hGUImain, $idDummy Global $nWGUImain = 220, $nHGUImain = @DesktopHeight Global $nXGUImain = 0, $nYGUImain = 0 Global $idLVmain, $hLVmain Global $nXLVmain = 5, $nYLVmain = 5 Global $nWLVmain = $nWGUImain - (2 * $nXLVmain) Global $nHLVmain = $nHGUImain - (2 * $nYLVmain) Global $bManage = False ; Schleifenvariable zum Öffnen 'Anwendungen verwalten' _Main_Create() ; Hotkey zum Ausblenden des Menüs an GUI-Main koppeln Global $aAccKeys[1][2] = [['{ESC}', $idDummy]] GUISetAccelerators($aAccKeys, $hGUImain) _Main_MenuSetEntries() ; Hotkey zum Einblenden des Menüs HotKeySet("^+m", "_Main_ShowGui") ; Strg+Umsch+M ; Hotkey zum Beenden der Anwendung HotKeySet("^!m", "_Exit") ; Strg+Alt+M GUIRegisterMsg($WM_NOTIFY, "_WM_NOTIFY") Global $aMsg While True If $bManage Then _GUICtrlListView_DeleteAllItems($hLVDel) _Manage_SetLVDelete() If IniRead($INI, 'winitem', 'logout', '0') = '1' Then GUICtrlSetState($cbLogout, $GUI_CHECKED) If IniRead($INI, 'winitem', 'restart', '0') = '1' Then GUICtrlSetState($cbRestart, $GUI_CHECKED) If IniRead($INI, 'winitem', 'shutdown', '0') = '1' Then GUICtrlSetState($cbShutdown, $GUI_CHECKED) $bManage = False GUISetState(@SW_SHOW, $hGuiNew) EndIf $aMsg = GUIGetMsg(1) Switch $aMsg[1] Case $hGUImain Switch $aMsg[0] Case $idDummy GUISetState(@SW_HIDE, $hGUImain) EndSwitch Case $hGuiNew Switch $aMsg[0] Case -3 GUISetState(@SW_HIDE, $hGuiNew) GUICtrlSetData($inAlias, '') GUICtrlSetData($inPath, '') $sPathLast = $PROGRAMFILES _Main_MenuSetEntries() GUISetState(@SW_SHOW, $hGUImain) Case $btSelect $sSel = FileOpenDialog('Anwendung', $sPathLast, 'Application (*.exe)', 1+2) If $sSel <> '' Then GUICtrlSetData($inPath, $sSel) $sPathLast = StringLeft($sSel, StringInStr($sSel, '\', 0, -1) -1) $sAlias = GUICtrlRead($inAlias) If $sAlias = '' Then $sAlias = StringTrimLeft($sSel, StringInStr($sSel, '\', 0, -1)) $sAlias = StringLeft($sAlias, StringInStr($sAlias, '.', 0, -1) -1) GUICtrlSetData($inAlias, $sAlias) EndIf GUICtrlSetState($btNext, $GUI_ENABLE) GUICtrlSetState($btEnd, $GUI_ENABLE) EndIf Case $btNext ; Zwischenspeichern If $aBuffer[0][0] <> Null Then ReDim $aBuffer[UBound($aBuffer)+1][2] $aBuffer[UBound($aBuffer)-1][0] = GUICtrlRead($inAlias) $aBuffer[UBound($aBuffer)-1][1] = GUICtrlRead($inPath) GUICtrlSetData($inAlias, '') GUICtrlSetData($inPath, '') Case $btEnd $sRes = '' If $aBuffer[0][0] <> Null Then For $i = 0 To UBound($aBuffer) -1 $sRes &= _IniWriteOnce($INI, 'apps', $aBuffer[$i][0], $aBuffer[$i][1]) & @CRLF Next ReDim $aBuffer[1][2] $aBuffer[0][0] = Null EndIf If GUICtrlRead($inAlias) <> '' And GUICtrlRead($inPath) <> '' Then $sRes &= _IniWriteOnce($INI, 'apps', GUICtrlRead($inAlias), GUICtrlRead($inPath)) & @CRLF GUICtrlSetData($inAlias, '') GUICtrlSetData($inPath, '') EndIf If $sRes <> '' Then MsgBox(262144+64, 'Übernahme Apps', $sRes) GUISetState(@SW_HIDE, $hGuiNew) _Main_MenuSetEntries() GUISetState(@SW_SHOW, $hGUImain) Case $cbLogout IniWrite($INI, 'winitem', 'logout', (BitAND(GUICtrlRead($cbLogout), $GUI_CHECKED) ? '1' : '0')) Case $cbRestart IniWrite($INI, 'winitem', 'restart', (BitAND(GUICtrlRead($cbRestart), $GUI_CHECKED) ? '1' : '0')) Case $cbShutdown IniWrite($INI, 'winitem', 'shutdown', (BitAND(GUICtrlRead($cbShutdown), $GUI_CHECKED) ? '1' : '0')) Case $btDel GUISetState(@SW_HIDE, $hGuiNew) ; Einträge mit entferntem Haken aus der INI löschen For $i = 0 To _GUICtrlListView_GetItemCount($hLVDel) -1 If Not _GUICtrlListView_GetItemChecked($hLVDel, $i) Then IniDelete($INI, 'apps', _GUICtrlListView_GetItemText($hLVDel, $i)) EndIf Next _Main_MenuSetEntries() GUISetState(@SW_SHOW, $hGUImain) EndSwitch EndSwitch WEnd Func _IniWriteOnce($_ini, $_section, $_key, $_value) ; Key kann nicht mit neuem Wert überschrieben werden Local $aSec = IniReadSection($_ini, $_section) If Not @error Then For $i = 1 To $aSec[0][0] If $aSec[$i][0] = $_key Then Return '"' & $_key & '" - [Fehler] Bereits vorhanden!' Next EndIf IniWrite($_ini, $_section, $_key, $_value) Return '"' & $_key & '" - [OK] Eingetragen' EndFunc Func _Exit() Exit EndFunc Func _Main_ShowGui() GUISetState(@SW_SHOW, $hGUImain) EndFunc Func _Main_Create() $hGUImain = GUICreate('', $nWGUImain, $nHGUImain, $nXGUImain, $nYGUImain, $WS_POPUP, $WS_EX_TOPMOST) GUISetIcon($SHELL32DLL, -323) $idDummy = GUICtrlCreateDummy() $idLVmain = GUICtrlCreateListView('', $nXLVmain, $nYLVmain, $nWLVmain, $nHLVmain) GUICtrlSetStyle($idLVmain, BitOR($LVS_NOCOLUMNHEADER,$LVS_SMALLICON)) $hLVmain = GUICtrlGetHandle($idLVmain) _GUICtrlListView_SetColumnWidth($hLVmain, 0, $LVSCW_AUTOSIZE_USEHEADER) EndFunc Func _Main_MenuSetEntries() ; Reset Size & Position WinMove($hGUImain, '', $nXGUImain, $nYGUImain, $nWGUImain, $nHGUImain) ControlMove($hGUImain, '', $idLVmain, $nXLVmain, $nYLVmain, $nWLVmain, $nHLVmain) _GUICtrlListView_DeleteAllItems($hLVmain) ; alle Einträge im Listview löschen $aApps = _ReadAppsFromINI() ; gespeicherte Apps aus INI lesen ; Eintrag für Verwaltung an Index 0 $aApps[0][0] = '>> EINTRÄGE VERWALTEN <<' $aApps[0][1] = 'Verwalten' ; Einträge für Abmelden, Neustart und Shutdown zufügen, wenn gewählt If IniRead($INI, 'winitem', 'logout', '0') = 1 Then ReDim $aApps[UBound($aApps)+1][2] $aApps[UBound($aApps)-1][0] = '>> ABMELDEN <<' $aApps[UBound($aApps)-1][1] = 'Sleep' EndIf If IniRead($INI, 'winitem', 'restart', '0') = 1 Then ReDim $aApps[UBound($aApps)+1][2] $aApps[UBound($aApps)-1][0] = '>> NEUSTART <<' $aApps[UBound($aApps)-1][1] = 'Restart' EndIf If IniRead($INI, 'winitem', 'shutdown', '0') = 1 Then ReDim $aApps[UBound($aApps)+1][2] $aApps[UBound($aApps)-1][0] = '>> HERUNTERFAHREN <<' $aApps[UBound($aApps)-1][1] = 'Shutdown' EndIf For $i = 0 To UBound($aApps) -1 _GUICtrlCreateListViewImgItem($aApps[$i][0], $idLVmain, $aApps[$i][1]) Next ; Position Menü (relativ zur Taskbar) & Größe (abhängig von Menüeinträgen) ändern Local $aView = _GUICtrlListView_GetItemRect($hLVmain, _GUICtrlListView_GetItemCount($hLVmain)-1, $LVIR_LABEL) Local $iDiffX = $aView[2] - ($nWGUImain - (2 * $nXLVmain)) ; Änderung der Listviewbreite für Anpassung Fensterbreite Local $iDiffY = $aView[3] - ($nHGUImain - (2 * $nYLVmain)) ; Änderung der Listviewhöhe für Anpassung Fensterhöhe Local $aWin = WinGetPos($hGUImain) Local $tTB = _GetTaskBarProps(True) Local $nX = $aWin[0], $nY = $aWin[1], $nW = $aWin[2], $nH = $aWin[3] Switch $tTB.sEdge Case 'LEFT' $nX = $tTB.right $nY = 0 Case 'TOP' $nX = 0 $nY = $tTB.bottom Case 'RIGHT' $nX = $tTB.left - $nW $nY = 0 Case 'BOTTOM' $nX = 0 $nY = $tTB.top - ($nH + ($iDiffY)) - $nYLVmain EndSwitch WinMove($hGUImain, '', $nX, $nY, $nW, $nH + ($iDiffY) + 2*$nYLVmain) ControlMove($hGUImain, '', $idLVmain, $nXLVmain, $nYLVmain, $nW - (2 * $nXLVmain), $nHLVmain + ($iDiffY) + 2*$nYLVmain) EndFunc Func _GUICtrlCreateListViewImgItem($_sText, $_idLV, $_sPathImg, $_iOrdImg=-1) Switch $_sPathImg Case 'Verwalten' $_sPathImg = $SHELL32DLL $_iOrdImg = -322 Case 'Sleep' $_sPathImg = $SHELL32DLL $_iOrdImg = -212 Case 'Restart' $_sPathImg = $SHELL32DLL $_iOrdImg = -239 Case 'Shutdown' $_sPathImg = $SHELL32DLL $_iOrdImg = -216 EndSwitch GUICtrlCreateListViewItem(' ' & $_sText, $_idLV) GuiCtrlSetImage(-1, $_sPathImg, $_iOrdImg) EndFunc Func _ReadAppsFromINI() Local $a = IniReadSection($INI, "apps") If Not IsArray($a) Then $a = StringSplit('|', '|', 2) ReDim $a[1][2] Else _ArraySort($a, 0, 1) EndIf Return $a EndFunc Func _Manage_CreateGUI() $hGuiNew = GUICreate('Anwendungen verwalten', 600, 400, 80, (@DesktopHeight/2 -200), -1, $WS_EX_TOPMOST) GUISetIcon($SHELL32DLL, -323) $hTab = GUICtrlCreateTab(10, 5, 580, 390) $tabNew = GUICtrlCreateTabItem('Neue Apps') GUICtrlCreateLabel('Programmpfad', 20, 53, 80) $inPath = GUICtrlCreateInput('', 100, 50, 455, 20, $ES_READONLY) $btSelect = GUICtrlCreateButton('...', 560, 50, 20, 20) GUICtrlCreateLabel('Anzeigename', 20, 83, 80) $inAlias = GUICtrlCreateInput('', 100, 80, 455, 20) _GUICtrlEdit_SetCueBanner($inAlias, 'Kurzname eintragen', True) GUICtrlCreateLabel('Eintrag Zwischenspeichern oder gespeicherte/aktuelle Daten Übernehmen', 100, 113) $btNext = GUICtrlCreateButton('Zwischenspeicher', 100, 140, 120, 20) GUICtrlSetState(-1, $GUI_DISABLE) $btEnd = GUICtrlCreateButton('Übernahme/Ende', 435, 140, 120, 20) GUICtrlSetState(-1, $GUI_DISABLE) GUICtrlCreateGroup(' Windows Menüeinträge (Änderungen werden beim Schließen des Fensters übernommen)', 20, 180, 560, 100) $icoLogout = GUICtrlCreateIcon($SHELL32DLL, -212, 128, 210, 32, 32, $SS_ICON) $icoRestart = GUICtrlCreateIcon($SHELL32DLL, -239, 268, 210, 32, 32, $SS_ICON) $icoShutdown = GUICtrlCreateIcon($SHELL32DLL, -216, 408, 210, 32, 32, $SS_ICON) $cbLogout = GUICtrlCreateCheckbox(' Abmelden', 100, 245, Default, Default, $BS_ICON) $cbRestart = GUICtrlCreateCheckbox(' Neu Starten', 230, 245, Default, Default, $BS_ICON) $cbShutdown = GUICtrlCreateCheckbox(' Herunterfahren', 370, 245, Default, Default, $BS_ICON) GUICtrlCreateGroup("", -99, -99, 1, 1) GUICtrlCreateTabItem('') $tabDel = GUICtrlCreateTabItem('Apps Löschen') GUICtrlCreateLabel('Für zu löschende Apps die Markierung entfernen', 20, 43) $btDel = GUICtrlCreateButton('Übernehmen', 500, 40, 80, 20) $LVDel = GUICtrlCreateListView('App|Pfad', 20, 65, 560, 325, BitAND(Default,$LVS_NOCOLUMNHEADER), _ BitOR($LVS_EX_CHECKBOXES,$LVS_EX_GRIDLINES)) $hLVDel = GUICtrlGetHandle($LVDel) _GUICtrlListView_SetColumnWidth($hLVDel, 0, 150) _GUICtrlListView_SetColumnWidth($hLVDel, 1, $LVSCW_AUTOSIZE_USEHEADER) GUICtrlCreateTabItem('') EndFunc Func _Manage_SetLVDelete() Local $aApp = _ReadAppsFromINI() If UBound($aApps) > 1 Then For $i = 1 To UBound($aApp) -1 GUICtrlCreateListViewItem($aApp[$i][0] & '|' & $aApp[$i][1], $LVDel) GUICtrlSetState(-1, $GUI_CHECKED) Next EndIf EndFunc Func _WM_NOTIFY($hWnd, $iMsg, $wParam, $lParam) #forceref $hWnd, $iMsg, $wParam Local $HWndLV = $hLVmain If Not IsHWnd($HWndLV) Then $HWndLV = GUICtrlGetHandle($HWndLV) Local $tNMHDR = DllStructCreate($tagNMHDR, $lParam) Local $hWndFrom = HWnd(DllStructGetData($tNMHDR, "hWndFrom")) Local $iCode = DllStructGetData($tNMHDR, "Code") Local $idx Switch $hWndFrom Case $HWndLV $idx = _GUICtrlListView_GetSelectedIndices($HWndLV) Switch $iCode Case $LVN_ITEMCHANGED ToolTip('') Case $NM_CLICK If $aApps[$idx][1] = "Verwalten" Then $bManage = True GUISetState(@SW_HIDE, $hGUImain) ElseIf $aApps[$idx][1] = "Sleep" Then GUISetState(@SW_HIDE, $hGUImain) Shutdown(0+32) ; $SD_LOGOFF ElseIf $aApps[$idx][1] = "Restart" Then GUISetState(@SW_HIDE, $hGUImain) Shutdown(1+2+4) ; $SD_LOGOFF + $SD_REBOOT + $SD_FORCE ElseIf $aApps[$idx][1] = "Shutdown" Then GUISetState(@SW_HIDE, $hGUImain) Shutdown(1+4+8) ; $SD_SHUTDOWN + $SD_FORCE + $SD_POWERDOWN Else ShellExecute($aApps[$idx][1]) GUISetState(@SW_HIDE, $hGUImain) EndIf Case $NM_RCLICK ToolTip($aApps[$idx][1]) EndSwitch EndSwitch Return $GUI_RUNDEFMSG EndFunc ;==>WM_NOTIFY ;=================================================================================================== ; Function Name....: _GetTaskBarProps ; Description......: gibt Eigenschaften und Position der Taskbar zurück ; Parameter(s).....: [optional] $_bReturnStruct - Rückgabe als (True) Struktur, (False - Standard) Array ; Return Value(s)..: Array / Struktur mit den Taskbarwerten ; Author...........: BugFix ;=================================================================================================== Func _GetTaskBarProps($_bReturnStruct=False) Local Const $ABM_GETSTATE = 0x4 ; specify the cbSize. Local Const $ABM_GETTASKBARPOS = 0x5 ; specify the cbSize. Local Const $ABM_GETAUTOHIDEBAR = 0x7 ; specify the cbSize and uEdge. Returns the handle to the autohide appbar ; ABM_GETSTATE Local Const $ABS_AUTOHIDE = 0x1 Local Const $ABS_ALWAYSONTOP = 0x2 ; ab Win7 nicht mehr!! --> wenn NICHT $ABS_AUTOHIDE ist es $ABS_ALWAYSONTOP ; uEdge - ABM_GETAUTOHIDEBAR Local Const $ABE_LEFT = 0 Local Const $ABE_TOP = 1 Local Const $ABE_RIGHT = 2 Local Const $ABE_BOTTOM = 3 Local $hWndAppBar = DllCall("user32.dll", 'long', "FindWindowA", 'str', "Shell_traywnd", 'str', "")[0] Local $iState, $iEdge, $hWnd, $shell32 = DllOpen("shell32") Local $tRC = DllStructCreate("struct;int left;int top;int right;int bottom;endstruct") Local $tAPPBARDATA = DllStructCreate("dword cbSize;int hWnd;uint;uint uEdge;int left;int top;int right;int bottom;int") $tAPPBARDATA.cbSize = DllStructGetSize($tAPPBARDATA) $tAPPBARDATA.hWnd = $hWndAppBar ; get pos $ret = DllCall($shell32, 'int', 'SHAppBarMessage', 'int', $ABM_GETTASKBARPOS, 'ptr', DllStructGetPtr($tAPPBARDATA)) For $i = 1 To 4 DllStructSetData($tRC, $i, DllStructGetData($tAPPBARDATA, $i+4)) Next ; get state $ret = DllCall($shell32, 'int', 'SHAppBarMessage', 'int', $ABM_GETSTATE, 'ptr', DllStructGetPtr($tAPPBARDATA)) $iState = $ret[0] ; get Edge If $iState = $ABS_AUTOHIDE Then For $i = 0 To 3 $tAPPBARDATA.uEdge = $i $ret = DllCall($shell32, 'int', 'SHAppBarMessage', 'int', $ABM_GETAUTOHIDEBAR, 'ptr', DllStructGetPtr($tAPPBARDATA)) $hWnd = $ret[0] If $hWnd Then $iEdge = $i ExitLoop EndIf Next DllClose($shell32) Else If $tRC.top < 1 And $tRC.left < 1 Then If $tRC.bottom > $tRC.right Then $iEdge = 0 If $tRC.right > $tRC.bottom Then $iEdge = 1 ElseIf $tRC.top < 1 And $tRC.left > 0 Then $iEdge = 2 Else $iEdge = 3 EndIf EndIf ; return array or structure: [.hWnd, .autohide(True/False), .uEdge(0..3), .sEdge(left..bottom), .left, .top, .right, .bottom] Local $aEdge[] = ['LEFT','TOP','RIGHT','BOTTOM'] Local $aRet[] = [$hWndAppBar, ($iState = $ABS_AUTOHIDE), $iEdge, $aEdge[$iEdge], $tRC.left, $tRC.top, $tRC.right, $tRC.bottom] Local $tRet = DllStructCreate('int hWnd;bool autohide;uint uEdge;char sEdge[' & StringLen($aEdge[$iEdge]) & '];int left;int top;int right;int bottom;') For $i = 0 To UBound($aRet) -1 DllStructSetData($tRet, $i+1, $aRet[$i]) Next Return ($_bReturnStruct ? $tRet : $aRet) EndFunc ;==>_GetTaskBarProps -

Viel Erfolg weiterhin
Jetzt tut sich ein anderes Problem auf, kann ich leider nicht im Testskript nachstellen.
In meiner Anwendung wird das Fenster im Hintergrund befüllt, die Größe angepasst und per Hotkey eingeblendet.
Mit Listview-UDF erstelltem Listview wird das Fenster angezeigt, mit nativ erstelltem Listview nicht.
Ich kann nur noch nicht nachvollziehen, was da so reingrätscht.EDIT:
Gefunden - Man darf den Style nicht beim Erstellen setzen, sondern hinterher mit GUICtrlSetStyle.
-
der Trick ist, einfach nicht _GUICtrlListView_Create zu benutzen 😅 .
He, Danke.
Meist verwende ich auch die nativen Funktionen. Da ich hier aber im Folgenden die Funktionen aus der UDF brauche, wollte ich konsequenterweise kpl. die UDF nutzen - falsch gedacht. -
Problem:
Ich erstelle ein Listview (ohne Header) und ordne den Item Icon zu. Aber die Einträge werden nebeneinander angeordnet und erst wenn die Listviewbreite erreicht ist, geht es in die nächste Zeile.
Ich habe schon verschiedene Stylekombis ausprobiert, aber ich bekomme es nicht hin, jeden Eintrag in einer Zeile anzuzeigen.Wo liegt mein Fehler?
Hier das Testskript
AutoIt
Alles anzeigen#include <GuiImageList.au3> #include <GuiListView.au3> Global $w_Gui = 400, $h_Gui = 200 Global $hGui = GuiCreate('', $w_Gui, $h_Gui) ; Listview erstellen Global $hLV = _GUICtrlListView_Create($hGui, '', 5, 5, $w_Gui-10, $h_Gui-10, BitOR($LVS_NOCOLUMNHEADER,$LVS_SMALLICON)) _GUICtrlListView_InsertColumn($hLV, 0, '') _GUICtrlListView_SetColumnWidth($hLV, 0, $LVSCW_AUTOSIZE_USEHEADER) ; ImageList erstellen Global $hImage = _GUIImageList_Create(24, 24) _GUIImageList_AddIcon($hImage, @WindowsDir & '\System32\SHELL32.dll', 156, True) _GUIImageList_AddIcon($hImage, @WindowsDir & '\System32\SHELL32.dll', 211, True) _GUIImageList_AddIcon($hImage, @WindowsDir & '\System32\SHELL32.dll', 238, True) _GUIImageList_AddIcon($hImage, @WindowsDir & '\System32\SHELL32.dll', 215, True) _GUICtrlListView_SetImageList($hLV, $hImage, 1) ; Item eintragen _GUICtrlListView_AddItem($hLV, " IRGENDEIN EINTRAG", 0) _GUICtrlListView_AddItem($hLV, " Logout", 1) _GUICtrlListView_AddItem($hLV, " Restart", 2) _GUICtrlListView_AddItem($hLV, " Shutdown", 3) GUISetState() Do Until GUIGetMsg() = -3 -
Hab jetzt die Hauptursache entdeckt. Das Userprofil wurde von einem Systemhaus, das unsere Technik betreut, erstellt. Und das sind in meinen Augen Vollidioten. In meinem Userzweig \Appdata habe ich NUR Leserechte. Was haben die denn gedacht, wozu ich den PC nutze - zum Zeitung Lesen?
Das werde ich dann nächste Woche klären.
-

Meine SciTEUser.properties liegt in C:\Users\<Username>\AppData\Local\AutoIt v3\SciTE
Ja, so kenne ich das seit Jahrzehnten - und nur so funktioniert es. Daher war ich verwirrt, diese im Programmordner vorzufinden. Zumal ein Erstellen im User-AppData nichts bringt, wenn SciTE zuerst im Programmordner sucht.

-
Ich habe an meinem Arbeitsplatz jetzt einen Rechner bekommen, der an unsere Domäne angeschlossen ist. Daher habe ich auch keine Adminrechte
 .
.Folgendes Problem:
Unter meinem Account wurde durch den Administrator AutoIt und SciTE4AutoIt installiert. Nun wollte ich Anpassungen in SciTE vornehmen - geht aber nicht, da die SciTEUser.properties bereits während der Installation erstellt wurde und völlig sinnfrei im Programmordner von SciTE gespeichert ist. Dort habe ich natürlich keine Schreibrechte. Ich kann somit auch nicht auf eine andere Startup.lua außerhalb des Programmordners verweisen. Das macht kein Spaß. Ebenso funktioniert zum Bsp. Autovervollständigung nicht. Also alles, was ich sonst über eigene Einstellungen in den Properties regele fällt flach. Da kann ich dann meine Programme gleich von Hand auf Papier schreiben - kaum ein Komfortunterschied.Hat jemand einen hilfreichen Gedanken?
-

Z.B. Syntax hervorheben. Das kann Notepad++ bei au3-Dateien sogar
Die Syntaxhervorhebung ist gerade das Hauptproblem bei NPP. Weil das nicht vernünftig angepasst werden kann, hatte ich damals das Projekt (Notepad++ und AutoIt) nicht weiter verfolgt.
-
Für die reine Nutzung des Editors zum Programmieren ist es mehr oder weniger egal, ob Scite oder VSCode.
Wer aber gern am Editor eigene Funktionalität haben möchte, findet in SciTE mehr Möglichkeiten auf Ereignisse zu reagieren (z.B. OnChar, OnKey).
Sollte die Entwicklung eingestellt werden, würde ich zumindest versuchen, ob ich die SciTE Variante aktuell halten kann. - Schaun wir ma. 😁
-

Hi Leute, erst einmal frohes neues Jahr.

Ich finde es aber ehrlich gesagt albern, dass man bei Problemen mit dem eigenen System in diesem Forum von Leuten "Windoof" lesen muss.
Den Scheiß bekommt man eh oft zu hören. Aber im Forum einer Programmiersprache, die komplett auf Windows aufsetzt und nur dort funktioniert? (Erspart mir bitte Wine Hinweise).Das ist verdammt peinlich. Ihr nutzt das System nicht nur; ihr nutzt es intensiv, sonst würdet ihr hier nicht schreiben. Kriegt euer Leben in den Griff.
Das, was du dort von dir gibst, ist peinlich.
Mein System lief Monate so, wie es sollte. Keine extraordinäre Software drauf - alles gut. Und dann nach einem Windows Update ging es los - Details oben beschrieben. Ich selber habe an meinem System nichts geschraubt. Das war ausschließlich Windows.
Ich nutze Windows seit der ersten Version. Wirklich stabil waren davon nur 3: Win 95, Win XP, Win 7. Alles, was Peter S. Taler zur Windows Entwicklung gesagt hat, kann ich absolut unterschreiben.
Wir sollen unser Leben in den Griff kriegen - was soll das bitte im Zusammenhang mit M$ Fehlentwicklungen bedeuten?
-
wie meinst Du das? .....keine Icon mehr angezeigt werden
Im gesamten Windows (Desktop, Explorerfenster) gab es keine Icon mehr, bzw. wurde auf dem Desktop für jeden Link ein- und dasselbe Icon verwendet, im Explorer und Menüs (Programme) jedoch gar keins.
Nur das WhatsApp-Icon wurde noch angezeigt - kein Wunder, die Installation ist so tief vergraben, die findet Windows nicht mal mehr selbst.