
Das ist im Grunde der Sinn dieser UDF: Höhere Mathematik nutzen ohne sich mit dieser auseinander setzen zu müssen.
Ja, das habe ich dann mißverständlich ausgedrückt.
Ich habe für diese UDF aktuell nicht das passende Problem.
Das ist im Grunde der Sinn dieser UDF: Höhere Mathematik nutzen ohne sich mit dieser auseinander setzen zu müssen.
Ja, das habe ich dann mißverständlich ausgedrückt.
Ich habe für diese UDF aktuell nicht das passende Problem.
Von Ingenieuren für Ingenieure
Ich fühlte mich auch ohne diesen Hinweis angesprochen, Herr Kollege![]()
Ich hatte mir schon im "blauen" Forum alles durchgelesen und auch die Beispiele durchforstet und damit experimentiert....sehr sehr feines Programmpaket!
Leider, und das meine ich mit tiefstem Respekt vor dieser immensen Arbeit, habe ich aktuell keine/kaum eine Anwendung dafür. Den mathematischen Hintergrund verstehe ich "halbwegs", von einigen Spezialitäten abgesehen.
Leider befasse ich mich weniger mit höherer Mathematik, für die meisten im Studium aufgezeigten Problemlösungen gibt es (in meinem Bereich) rudimentäre Software, ansonsten nutze ich meistens das von mir schon seit etlichen Jahren selbstprogrammierte Handwerkszeug. Meßreihen erstellt und ausgewertet hatte ich vor Jahrzehnten einmal (DMS Dehnungsmeßstreifen zur Drehmoment- und Kraftanalyse an Stahlprofilen), dafür hätte ich so ein Programm gut brauchen können....
Aber für "automatisierte" Datenanalysen gibt es jetzt AutoIt und eine Adjustment UDF. Ich gehe davon aus, wenn sich das in den entsprechenden (Anwender-) Kreisen rumspricht, werden definitiv Anfragen kommen![]()
Das ist die "alte" Variante.
Die "neuere" ist nur auf github, nicht in der Download-Datei
Ansonsten funzt das einwandfrei!
und so mit dem binary
den bekommt man nach dem $mCode = _JIT_Compile($sSourceCode)mit $mCode.BinaryString
#AutoIt3Wrapper_UseX64=y
#include <GDIPlus.au3>
#include "JIT.au3"
Global $sSourceCode = _
' CALLCONV void XorTexture(unsigned int* ptr, int iW, int iH) { ' & @LF & _
' for (int y = 0; y < iH; y++) { ' & @LF & _
' unsigned int yy = y * iW; ' & @LF & _
' for (int x = 0; x < iW; x++) { ' & @LF & _
' unsigned int r = ( x ^ y ) & 0xFF; ' & @LF & _
' unsigned int g = ((x >> 1) ^ (y >> 1)) & 0xFF; ' & @LF & _
' unsigned int b = ((x * 3) ^ (y * 5) ) & 0xFF; ' & @LF & _
' ptr[yy + x] = (0xFF << 24) | (r << 16) | (g << 8) | b; ' & @LF & _
' } ' & @LF & _
' } ' & @LF & _
' }'
;~ Global $mCode = _JIT_Compile($sSourceCode)
;~ If @error Then Exit MsgBox(16, "Error", "Compilation failed")
;ConsoleWrite('@@ Debug(' & @ScriptLineNumber & ') : $mCode.BinaryString = ' & $mCode.BinaryString & @CRLF & '>Error code: ' & @error & @CRLF) ;### Debug Console
_GDIPlus_Startup()
Global $iW = 1200, $iH = 800
Global $pScan0 = DllStructCreate("ulong rgba[" & $iW * $iH & "]")
Global $hBitmap = _GDIPlus_BitmapCreateFromScan0($iW, $iH, $GDIP_PXF32ARGB, $iW * 4, $pScan0)
Global $sBinary ="4585C00F8E83000000415455575689D65385D27E704889CB4489C731C94531C04C63DA66662E0F1F84000000000066904489C0448D148931D24C8D0C830F1F0089CD8D045231D54431D04189EC0FB6C0C1E50741C1E41081E500FF00004181E40000FF004409E009E80D000000FF418904914883C2014939D375C583C1014101F039CF75AB5B5E5F5D415CC3C3"
; load the binary into executable memory - no API call needed!
Global $mCode = _JIT_LoadBinary($sBinary)
If @error Then Exit MsgBox(16, "Error", "Failed to load binary")
Global $aDll = DllCallAddress("none", $mCode.ptr, "ptr", DllStructGetPtr($pScan0), "int", $iW, "int", $iH)
Global $hGUI = GUICreate("JIT Test", $iW, $iH)
GUISetState(@SW_SHOW, $hGUI)
Global $hGfx = _GDIPlus_GraphicsCreateFromHWND($hGUI)
_GDIPlus_GraphicsDrawImageRect($hGfx, $hBitmap, 0, 0, $iW, $iH)
Do
Until GUIGetMsg() = -3
_GDIPlus_GraphicsDispose($hGfx)
_GDIPlus_BitmapDispose($hBitmap)
_GDIPlus_Shutdown()
_JIT_Free($mCode)//EDIT
Mit der Compileroption -O3 wird zwar mehr (assembler-)code erzeugt, der läuft dafür aber 2,5x schneller!
Global $mCode = _JIT_Compile($sSourceCode,"-O3")
klappt bei mir
#AutoIt3Wrapper_UseX64=y
#include <GDIPlus.au3>
#include "JIT.au3"
Global $sSourceCode = _
' CALLCONV void XorTexture(unsigned int* ptr, int iW, int iH) { ' & @LF & _
' for (int y = 0; y < iH; y++) { ' & @LF & _
' unsigned int yy = y * iW; ' & @LF & _
' for (int x = 0; x < iW; x++) { ' & @LF & _
' unsigned int r = ( x ^ y ) & 0xFF; ' & @LF & _
' unsigned int g = ((x >> 1) ^ (y >> 1)) & 0xFF; ' & @LF & _
' unsigned int b = ((x * 3) ^ (y * 5) ) & 0xFF; ' & @LF & _
' ptr[yy + x] = (0xFF << 24) | (r << 16) | (g << 8) | b; ' & @LF & _
' } ' & @LF & _
' } ' & @LF & _
' }'
Global $mCode = _JIT_Compile($sSourceCode)
If @error Then Exit MsgBox(16, "Error", "Compilation failed")
_GDIPlus_Startup()
Global $iW = 1200, $iH = 800
Global $pScan0 = DllStructCreate("ulong rgba[" & $iW * $iH & "]")
Global $hBitmap = _GDIPlus_BitmapCreateFromScan0($iW, $iH, $GDIP_PXF32ARGB, $iW * 4, $pScan0)
Global $aDll = DllCallAddress("none", $mCode.ptr + $mCode.Funcs["XorTexture"], "ptr", DllStructGetPtr($pScan0), "int", $iW, "int", $iH)
Global $hGUI = GUICreate("JIT Test", $iW, $iH)
GUISetState(@SW_SHOW, $hGUI)
Global $hGfx = _GDIPlus_GraphicsCreateFromHWND($hGUI)
_GDIPlus_GraphicsDrawImageRect($hGfx, $hBitmap, 0, 0, $iW, $iH)
Do
Until GUIGetMsg() = -3
_GDIPlus_GraphicsDispose($hGfx)
_GDIPlus_BitmapDispose($hBitmap)
_GDIPlus_Shutdown()
_JIT_Free($mCode)Ich konnte die Relokationen schlussendlich auflösen indem ich das ganze zweimal kompiliere (mit unterschiedlichen Parametern) und dort dann die Relocations entsprechend ersetzen kann.
Das war der Durchbruch.
Ich habe am Wochenende damit experimentiert, andere als C++-Compiler via _JIT_Compile() von der godbolt-Website einzusetzen. Funktioniert soweit bei einfachen Beispielen. Btw., die dort verwendeten Tools, u.a. Analysis und die angehängte KI-Erklärung (Claude Explain) und davon vorgeschlagenes Verbesserungspotential sind beeindruckend!
_JIT_Compile() hat definitiv Potential! Jetzt gibt es kaum noch einen Grund, AutoIt nicht auch für "schnelle" Berechnungen benutzen zu können.
Ich fände es besser, den C-Code direkt "inline" anzusprechen, wesentlich einfacher zu schreiben und zu debuggen. In AssembleIt hatte ich dazu eine kleine Funktion geschrieben, um den Code bspw. zwischen #cs und #ce schreiben/kopieren zu können.
Global $sSourceCode = _
'CALLCONV double hypotenuse(double a, double b) { ' & @LF & _
' return __builtin_sqrt(a * a + b * b); ' & @LF & _
'} ' & @LF & _
' ' & @LF & _
'CALLCONV double clamp(double val, double lo, double hi) { ' & @LF & _
' return __builtin_fmin(__builtin_fmax(val, lo), hi); ' & @LF & _
'} ' & @LF & _
' ' & @LF & _
'CALLCONV double roundDown(double x) { ' & @LF & _
' return __builtin_floor(x); ' & @LF & _
'}'vs
#cs
Global $sSourceCode = _
CALLCONV double hypotenuse(double a, double b) {
return __builtin_sqrt(a * a + b * b);
}
CALLCONV double clamp(double val, double lo, double hi) {
return __builtin_fmin(__builtin_fmax(val, lo), hi);
}
CALLCONV double roundDown(double x) {
return __builtin_floor(x);
}
#ceIch verweise HIER auf den ursprünglichen Thread von AspirinJunkie.
Mit dem Hintergrund, WIE erfolgreiches Development funktioniert bzw. funktionieren sollte.
Man MUSS einfach erwähnen, dass es jede Menge teilweise jahrelange Arbeit, Recherche, Schweiß, Geduld, Motivation, Lernbereitschaft, Neugier und viele weitere Eigenschaften braucht, um solch ein Projekt durchzuführen.
Letztendlich hat es ja geklappt ![]() , meinen tiefen Respekt dafür!
, meinen tiefen Respekt dafür!
Sehr nice!![]()
Bin nicht der C(++)-Freak, aber am Testen ![]() . Wir waren damals ja an der "direkten" Übermittlung des assemblierten Codes an den Assembler hängengeblieben....
. Wir waren damals ja an der "direkten" Übermittlung des assemblierten Codes an den Assembler hängengeblieben....
Frohes Fest allen und geruhsame Feiertage!
Und....einen guten Rutsch!

Ich habe mir nach etwas über 10 Jahren mal wieder einen neuen PC zusammengestellt (ja, auch wegen Win11).
Haha....hatte ich vor 6 Wochen auch gemacht![]()
Wurde ein Ryzen 9600X und ein Asrock B850M Pro-A Wifi (auch mit einem PCIe Gen5 Steckplatz für SSD) , 32GB RAM habe ich mir auch dazu gegönnt, war alles in allem mit 400,-€ recht günstig. Graka habe ich meine alte RX590 mit 8GB RAM behalten.
Ich hatte bereits schon eine Samsung 860 EVO SSD (SATA, kein NVME) als Root-Laufwerk und einige SSD und HDD als Datengräber. Eine Noname NVMe-SSD PCIe 3 hatte ich auch noch rumfliegen, auf die hatte ich die SATA SSD vor dem Upgrade Win10 auf 11 geklont, sicher ist sicher.
Der Umzug von Win10 home auf 11 (pro gekauft für 15€) lief extrem unspektakulär mit einigen Mausklicks, somit kann ich dem nur zustimmen ->
Mal so als kleiner Wink an die Fraktion mit der Nostalgiebrille die heute über Win11 herziehen und glauben es war früher besser.
Trotz "langsamer" SATA-SSD rennt der Rechner jetzt wesentlich schneller, auch der testweise Umzug (klonen) auf die NVMe-SSD brachte bei meinen Anwendungen keinen (messbaren) Geschwindigkeitsvorteil.
Da in einer der letzten c´t PCIe 4 und 5-SSDs getestet wurden, dachte ich an ein SSD-Upgrade. Soll ja "viiiieeeellll" schneller sein.
Jaja, schneller ist besser, aber wieviel schneller ist wieviel besser?!
Während ich diesen Text schreibe, befindet sich mein Prozessor im absoluten Ruhezustand, selbst bei grafikintensiven Games langweilt sich mein Prozessor....und die SSD? Hmmm...ja ,
Nur wenn ich ehrlich bin: Ich merke davon schlicht nichts im Alltag im Vergleich zu vorher.
so gehts mir auch![]() . Spiele laden schneller? Wie denn, was denn?! Ob ich beim Start des Games 3 Sekunden oder 5 warte, geht mir ehlich gesagt am Ar*** vorbei, die Zwischensequenzen skippe ich sowieso, und wenn ich mit Freunden zusammen im Discord quatsche beim Zocken merke ich immer wieder, dass eine stabile und geschmeidig laufende Internetverbindung 1000x wichtiger ist, als 5 FPS mehr oder weniger...Ladebildschirme muss man nur progressiv nutzen
. Spiele laden schneller? Wie denn, was denn?! Ob ich beim Start des Games 3 Sekunden oder 5 warte, geht mir ehlich gesagt am Ar*** vorbei, die Zwischensequenzen skippe ich sowieso, und wenn ich mit Freunden zusammen im Discord quatsche beim Zocken merke ich immer wieder, dass eine stabile und geschmeidig laufende Internetverbindung 1000x wichtiger ist, als 5 FPS mehr oder weniger...Ladebildschirme muss man nur progressiv nutzen![]() , Radler aus dem Kühlschrank holen und ne Tüte Chips...das dauert IMMER länger als die paar Sekunden um die Gigabytes an Grafikdaten zu laden
, Radler aus dem Kühlschrank holen und ne Tüte Chips...das dauert IMMER länger als die paar Sekunden um die Gigabytes an Grafikdaten zu laden ![]()
Und beim bearbeiten von "großen" Videodateien oder Bildern rege ich mich eher über meine Unbeholfenheit und eigenes Unvermögen auf als über die paar Millisekunden mehr Lade- und Speicherzeit...
Oscar ,
"Deine" SSD hat mir schon vor nem dreiviertel Jahr gefallen https://www.heise.de/news/Crucial-P…t-10228576.html
Wenn ich mal mehr Speicher brauche, ist das definitiv eine Option![]()
Hi,
1 Monitor, Win11, 1440p Desktop mit Fensterinhalt ohne Bewegung (KEINE Mausbewegung) FPS 3, Index 15, Dateigröße 185kB
Target fps: 30
Recording time: 20 seconds
Recording screen dim: 2560 x 1440
Starting fullscreen capturing in 3 seconds...
kmin: 24
kmax: 38
ellapsed: 20.08690979999938 seconds
frames captured: 66 3.28572192821825 fps
frame index: 305 15.18401800161464 fps
delta : 239 0.2163934426229508 %
total frames: 600 target fps 30 delta: 0.5083333333333333 %
File size: 184766 bytes
Done
Gleicher Desktopinhalt, während der "Aufnahme" aber exzessive Mausbewegung...Von 3 auf über 30FPS (s. unten)...Die API nimmt nur geänderte Bildschirme auf, wenn sich nichts ändert, wird auch nichts gerendert, es entsteht kein Frame und somit auch keine FPS, das hatte ich schon bei der Duplication-API angesprochen, das ist kein Bug, sondern ein Feature! Die letztendliche Bewertung kann nur über die Qualität/Größe der resultierenden webp-Datei erfolgen.
Target fps: 30
Recording time: 20 seconds
Recording screen dim: 2560 x 1440
Starting fullscreen capturing in 3 seconds...
kmin: 24
kmax: 38
ellapsed: 20.02609329999996 seconds
frames captured: 607 30.31045501021416 fps
frame index: 607 30.31045501021416 fps
delta : 0 0 %
total frames: 600 target fps 30 delta: 1.011666666666667 %
File size: 385894 bytes
Done
Bei actionreichem Video im Fullscreen komme ich auf ca. 15 FPS, Dateigröße um die 60MB
Wenn der Bildschirminhalt größtenteils "geblured" ist und sich bewegt, entstehen massive Artefakte in der *.webp-Datei

Ich denke, das reicht, um mal schnell den Desktop aufzunehmen, um z.B. was mit anderen zu teilen.
![]() ...wenn man einen Codec für die Anzeige hat...
...wenn man einen Codec für die Anzeige hat...
Anscheinend wird ein falsches Device ausgesucht:
*EDIT*
Ja, das letzte gefundene wird verwendet...incl. des Bildschirms/Screens....das ist das aktuell verwendete, d.h. die "aktuelle Grafikkarte (oder APU/GPU)"
Ich ändere das mal testweise auf das erste gefundene Device, das sollte immer funktionieren
TEST padapter DUP-API Example GPU APU .zip
Ok, habe jetzt die Framegrößen (GUI- und Buffer-Größen) auf 64-Pixel Grenzen erweitert (256 Byte Alignment statt 16 Byte Alignment). s. dazu auch hier https://asawicki.info/news_1726_secr…ource_alignment
In den "früheren" D3D-Versionen war das imho noch nicht so krass...Normalerweise kümmert sich der Treiber ums Alignment.![]()
Hehe, naja, "ältere API", das Posting ist einige Jahre zu spät (Orginal ist von 2021^^) ...![]() egal, Deskstream läuft in Autoit als Client/Serveranwendung, captured "natürlich" auch Fenster und Regions und nutzt eine OpenCL-basierte BC1-Kompression und Dekompression.
egal, Deskstream läuft in Autoit als Client/Serveranwendung, captured "natürlich" auch Fenster und Regions und nutzt eine OpenCL-basierte BC1-Kompression und Dekompression.
Alles nativer AutoIt-Code (bis auf eine Handvoll Bytes Maschinencode fürs Decompress ![]() (MUSS sein)) , lokal auf einer Maschine (Netzwerk = loopback Adapter 127.0.0.1) werden 60 FPS in 1440p "übertragen". Übers WLAN sind immer noch stabile 30+ FPS drin, das reicht um x-beliebige Bildschirminhalte auf bspw. einen Fernseher zu streamen (soviel zum "geschützten" 1&1-TV im Browser....)
(MUSS sein)) , lokal auf einer Maschine (Netzwerk = loopback Adapter 127.0.0.1) werden 60 FPS in 1440p "übertragen". Übers WLAN sind immer noch stabile 30+ FPS drin, das reicht um x-beliebige Bildschirminhalte auf bspw. einen Fernseher zu streamen (soviel zum "geschützten" 1&1-TV im Browser....)
Zur WinRT Capture API:
Habs jetzt nur oberflächlich betrachtet, aber D3D-Anwendungen waren doch schon immer dafür bekannt, keine "geschützten" Modi aufnehmen zu können?! DRM-gesicherte Anwendungen, Spiele, usw? Geht das jetzt mit der WinRT?
Weiterhin bin ich mit deiner Liste nicht einverstanden! ALLE von dir mit der DUP-API (nicht) angehakten Punkte sind ausschließlich NACH dem Screencapture ausgeführte D3D-Funktionen...bis auf den Cursor, den kann man bei der DUP-API auch per Flag nicht mit aufnehmen, der hat mich auch einiges an Nerven gekostet, da der Cursor extra "bearbeitbar" ist.
Dirtyregions und movedregions sind als ebenfalls schon in der API abfragbar...
Einfachheit für Win32/UWP
made my Day![]() ....aber da werde ich wie seit Jahrzehnten wieder auf Unverständnis seitens der Programmiererzunft stoßen. Der einzige Grund, wieso "Programmieren" so kompliziert war und immer noch ist, ist die Profilneurose und Featuritis der Programmierer(zunft). Wieso müssen immer und immer wieder etliche Funktionen und Aufrufe getätigt werden, um eine simple und milliardenfach abgefragte Aufgabe abzuwickeln? Ist da niemand in der Lage, einen Wrapper zu schreiben, der die Aufgabe in einer Zeile Code abliefern kann? Stattdessen schreibt einer vom anderen ab (heutzutage c&p), produziert millionenfach immer die gleichen Zeilen Code und wundert sich dann, wieso sein Job von einer strunzdummen, wahrscheinlichkeitsoptimierten "KI" übernommen werden kann....und wer jetzt quiekt sollte sich fragen, wieso mittlerweile Jahresgehälter im acht- bis neunstelligen Bereich für talentierte "KI-Forscher" bezahlt werden. Wieso wird deren Job nicht von einer KI übernommen
....aber da werde ich wie seit Jahrzehnten wieder auf Unverständnis seitens der Programmiererzunft stoßen. Der einzige Grund, wieso "Programmieren" so kompliziert war und immer noch ist, ist die Profilneurose und Featuritis der Programmierer(zunft). Wieso müssen immer und immer wieder etliche Funktionen und Aufrufe getätigt werden, um eine simple und milliardenfach abgefragte Aufgabe abzuwickeln? Ist da niemand in der Lage, einen Wrapper zu schreiben, der die Aufgabe in einer Zeile Code abliefern kann? Stattdessen schreibt einer vom anderen ab (heutzutage c&p), produziert millionenfach immer die gleichen Zeilen Code und wundert sich dann, wieso sein Job von einer strunzdummen, wahrscheinlichkeitsoptimierten "KI" übernommen werden kann....und wer jetzt quiekt sollte sich fragen, wieso mittlerweile Jahresgehälter im acht- bis neunstelligen Bereich für talentierte "KI-Forscher" bezahlt werden. Wieso wird deren Job nicht von einer KI übernommen![]() ?
?
Um meinen Punkt klarzustellen:
Ich hätte MONATE (zugegeben in ein "Hobby") investierte Zeit sparen können, wenn ich in AutoIt eine Funktion des Betriebssystems(!) hätte aufrufen können die da lautet
$ret = _DuplicationAPI_CaptureNextFrame() ;sets $tFrameData.PointerToPixel and $tFrameData.SizeOfPixels
OHNE tausende Zeilen *.h-Files und Interfacebeschreibungen per eigens dafür geschriebenen AutoIt-Script "automatisch" in AutoItcode überführen zu müssen. Und dazu noch hunderte Zeilen Code um imho völlig sinnlos hunderte Unterfunktionen aneinanderreihen zu müssen...
Und wenn ich die zugegeben nur oberflächlich verfolgten Threads zu deiner Umsetzung der WinRT Capture API verfolge, ist das bei dir ähnlich....soviel zum Thema EINFACHHEIT![]() ,
,
So wie das für mich aussieht, ist bei der WinRT Capture API ausschließlich Multithreading ein Feature, wieso das jemand aber bei einer Capturezeit in AutoIt (hust hust) von teilweise weit weniger als einer Millisekunde (reine Capturezeit) braucht, sei dahingestellt. weiterhin ist das auch keine "Low-Level" DXGI Anwendung?! Kommt mir vor wie von M$ gegängelt um als "modern" = "eingeschränkt" = "Win11-konform" = "nicht Low-Level" in die Anwendungen gedrückt zu werden
Viel interessanter in diesem Zusammenhang ist, dass in den Prozessor integrierte GPUs (also APU´s) einen enormen Geschwindigkeitsvorteil haben, da der Speicherbereich einer "externen" Grafikkarte nicht mehr grottenlangsam ![]() per DMA ins RAM transferiert werden muss, sondern dort direkt im Zugriff ist. "Fette" Prozessorcaches lassen zusätzlich Grüßen....
per DMA ins RAM transferiert werden muss, sondern dort direkt im Zugriff ist. "Fette" Prozessorcaches lassen zusätzlich Grüßen....
ich sehe nur ein schwarzen Bildschirm. Irgendwas scheint da nicht zu laufen.
d3d11 autoit_orginal plus 25 rendern nur gpu TEST APU.zip funktioniert? Deine Bildschirmauflösung?
Habe eben gerade meine heute erhaltene APU im Ryzen 9600X getestet, die wollte bei bestimmten GUI-größen auch nicht rendern...ich vermute, ich habe wieder mal für die sich ändernde GUI-Größe im Beispiel die Bitmapgrößen nicht als 32-Bit-Vielfache berechnet....dann wird nicht gerendert. Schon blöd, wenn uralte Hardware toleranter gegen "Programmierfehler" ist, wie neues Zeugs![]()
Hi zusammen,
hallo UEZ,
ich werkele schon einige Jahre (mit vielen arbeitsbedingten Unterbrechungen) an Deskstream, einem schnellen Programm zur Übertragung von Bildschirminhalten übers Netzwerk in Echtzeit.
Teamviewer macht das auch, aber arschlangsam....jedenfalls in der damaligen Version :o)
Problem u.a. war das Screenshotten in einer halbwegs guten Geschwindigkeit. Alles was mit GDI(+) zu tun hat, fällt damit schon mal raus, in den letzten Jahren hatte ich dazu schon etliches gepostet.
Nach bissl rumsuchen stolperte ich über die Interface-getriebene Microsoft Duplication API . Diese transferiert Bildschirminhalte in den Speicher, sobald sich auch nur ein Pixel geändert hat. Wenn sich nichts ändert, gibt es auch keinen neuen Screenshot! Die Geschwindigkeit ist im Vergleich zu anderen Methoden atemberaubend, ich habe eine Bildschirmauflösung von 2560x1440 und kann problemlos bis zu 120 Frames pro Sekunde an meinem Desktoprechner aufnehmen...
Auf einem Uralt-Win10-Tablet (Acer Switch10 von 2014) grabbe und blitte ich den Bildschirminhalt mit bis zu 55fps...wenn der Bildschirm gedreht wird, erkennt die API das und "dreht" mit.
Was ich als Beispielcode zur API vorfand, auch orginaler M$-Code, war gelinde gesagt eine Katastrophe und meist nicht (richtig) lauffähig. Die Interfaces waren teilweise falsch beschrieben, Implementierungen von Funktionen haarsträubend...nur sehr wenige Beispiele haben mehr als einen Frame gecaptured.....
Egal, ich habe mich reingekniet und hatte nach einigen Monaten(!) lauffähigen AutoItcode. Das schwierigste war die Implementierung und Umsetzung der Interfaces. Dabei habe ich etliche Optimierungen zu den Beispielcodes herausgefunden, die wichtigste Optimierung war imho, dass ich (entgegen ALLER verfügbaren Beispiele und Programme) nur EINMAL sämtliche Pointer und Interfaces initialisiert habe, statt ständig in einer Schleife alle Pointer und Interfaces für jeden einzelnen Frame neu zu initialisieren....wieso ist das noch keinem anderen Programmierer auf der Welt aufgefallen?!
Anbei ein kleines Beispiel.
Es wird eine GUI erstellt in welche der aktuelle Bildschirminhalt geblittet wird. Die GUI verändert Ihre Größe und parallel dazu auch den Zoom des Desktops. Dank D2D/D3D-Anbindung (auch der API) funktioniert das auch in nativem AutoItcode sehr flott. Da NUR GEÄNDERTE Bildschirminhalte von der API erfasst werden habe ich so etwas Bewegung auf den Screen gebracht. Man merkt sofort den Unterschied in den FPS, wenn man die Maus bewegt, dann steigt die FPS von 60-75 (ich habe einen 75HZ Monitor) auf über 120 FPS....
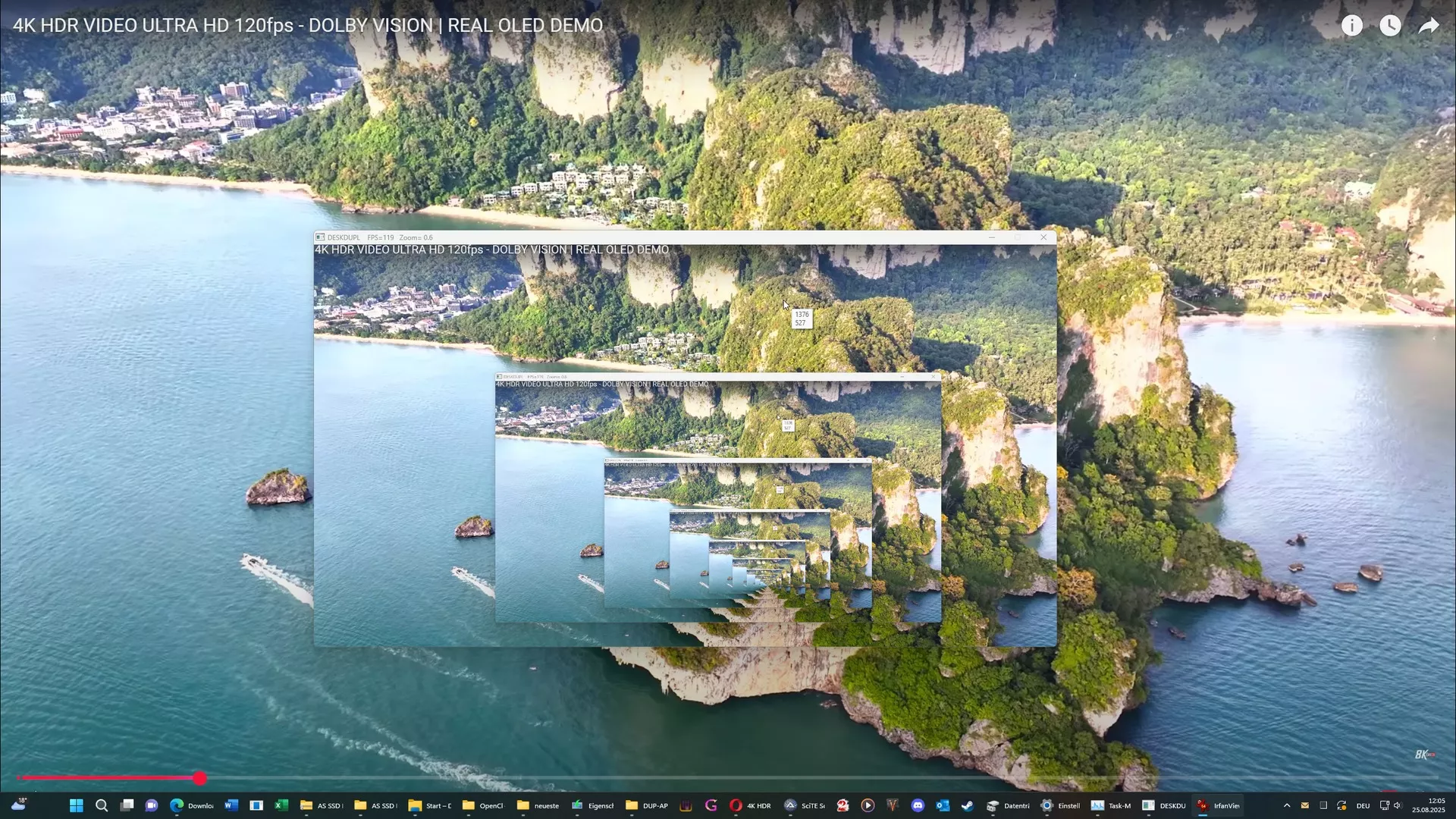
Wer mag, kann ja mal "nebenbei" ein 4K HDR-Video auf Youtube im Fullscreen laufen lassen und dabei die AutoIt-GUI einblenden.
Programm wie immer bei mir etwas chaotisch :o), Fragen dazu gerne, ich habe die letzte Version vor 3 Jahren bearbeitet ![]() Es wird aktuell das erste von der API gefundene Device (Monitor) benutzt, das kann aber bei Multimonitorsystemen eingestellt werden.
Es wird aktuell das erste von der API gefundene Device (Monitor) benutzt, das kann aber bei Multimonitorsystemen eingestellt werden.
Die API-Funktionen, wie immer bei mir, NICHT in einer der "schönen" UDF-Versionen (wo ist der "Fuck off"-Smilie![]() )
)
Einfach nach GND tasten.
yepp, die Arduinos sind in dieser Beziehung ziemlich robust und auch herzhaft zu beschalten.
Serial.println() ist dein Freund....so kannst du relativ einfach deinen Code nachverfolgen.
In der "neuen" IDE soll es einen integrierten Debugger geben, davon habe ich aber nur gelesen.
Hi,

in der kategorie Ü50 (noch),
Willkommen im Club! ![]()
ich finde bildung bzw. fortbildung total wichtig. jeder tag an dem man nichts neues lernt, ist ein schlechter tag.
Dito!
ich halte nichts davon, denn auf 'papier' kann ich es umsetzen und ich moechte wissen ob es auch wirklich geht wie ich es mir vorstelle.
Na dann los! Her mit deiner Idee, schaumamal was sich umsetzen lässt...
hmmmm....bis um ca. 23.30 Uhr im Chat noch bissl dumm Zeuch gesabbelt, dann ins Bett gegangen....nach ca. 20 Minuten festgestellt, das Script hatte ich gar nicht gepostet...![]()
Die Lösungen hier mit meiner verglichen und festgestellt, da war doch was mit dem Startpost und der zu herunterzuladenden Datei. ![]()

Hinweis: Das ist die Lösung für die heruntergeladene Datei (die nur 14 Zeichen erfordert).
Ja, so ging es mir auch!

Auf die Zeit habe ich nur bedingt geachtet, wird aber irgendwo um die 30 Minuten liegen.
hehe, ca. 2,5x so schnell wie ich....![]() s. die "verbotene" Kommentarzeile!
s. die "verbotene" Kommentarzeile!
Global $LineStart = @ScriptLineNumber
Func _CreateID($aUserdata)
Local $Return
$nachname = StringReplace($aUserdata[2], "+", "") & "99999" ; BINDESTRICH "IGNORIERT"...das hat mich 30 Minuten gekostet um von 90% auf 100% zu kommen!
$nachname = StringLeft($nachname, 5)
$jahr = StringRight($aUserdata[3], 2)
$jahr = StringLeft($jahr, 1)
$monat = StringMid($aUserdata[3], 4, 2)
If $aUserdata[4] = "W" Then $monat = String(Number($monat) + 50)
$tag = StringLeft($aUserdata[3], 2)
$jahreszahl = StringRight($aUserdata[3], 1)
$anfang = StringLeft($aUserdata[0], 1) & StringLeft($aUserdata[1], 1) & "99"
$anfang = StringLeft($anfang, 2)
$string = $nachname & $jahr & $monat & $tag & $jahreszahl & $anfang
$quersumme = $string
$z = 0
For $i = 1 To StringLen($quersumme)
$z = $z + Asc(StringMid($quersumme, $i, 1))
Next
while StringLen($quersumme) > 1
$quersumme = $z
$z = 0
For $i = 1 To StringLen($quersumme)
$z = $z + StringMid($quersumme, $i, 1)
Next
wend
$Return = $string & $quersumme
Return $Return
EndFunc ;==>_CreateID
Global $LineEnd = @ScriptLineNumberSchnuffel, klasse Sache das! Vielen Dank für deine Mühe!

ist es aber um Welten besser und angenehmer als light mode.
sehe (sic^^) ich NICHT so! Ich habe immer mal in den letzten Jahren den "dark mode" getestet und bin nach einigen Minuten (IMMER aus den von fast allen hier o.g. Gründen!!) wieder zum "hellen" Modus zurückgekehrt.
Ich persönlich kann auch nichts mit einem Darkmode anfangen...kein einziges Printmedium/Buch ist lesbarer im Darkmode, mir zumindest ist auch nicht ein einziges relevantes bekannt!
Keine mir bekannte Oberfläche einer Maschine im Produktionsbetrieb hat Darkmode, keine "Lichtwand" oder Werbetafel benutzt Darkmode. Schon mal eine professionelle Präsentation im Darkmode gesehen?!
Wer daheim alleine vor der Glotze sitzt und an seiner Software rumklimpert, der soll das wegen mir einstellen können wenn die persönlichen Vorteile überwiegen.

VSCode ist nur ein Beispiel wie man das super umsetzen kann.
Das erste, was ich da nach der Installation gemacht hatte, war auf "light" umzustellen :o)
Aber der VSCode "light mode" ist derart beschissen umgesetzt, dass ich nach Ausprobieren sämtlicher Modi im "Tomorrow Night blue" hängengeblieben bin. Erinnert mich an selige DOS-Zeiten (sollte Novell DOS gewesen sein) mit dem schönen blauen Hintergrund auf der Konsole ![]() . Jetzt die Frage an die Gemeinde: Wird der Darkmode bei VSCode nur genutzt/geschätzt, weil der Lightmode dermaßen mies ist? Wäre zumindest mal nachfragewürdig.
. Jetzt die Frage an die Gemeinde: Wird der Darkmode bei VSCode nur genutzt/geschätzt, weil der Lightmode dermaßen mies ist? Wäre zumindest mal nachfragewürdig.
![]() Habe jetzt DOCH ein Gerät gefunden, auf dem ich so etwas wie den "Darkmode" nutze, meine Fitnessuhr
Habe jetzt DOCH ein Gerät gefunden, auf dem ich so etwas wie den "Darkmode" nutze, meine Fitnessuhr![]() Aber dort auch nur, weil sämtlichen anderen 10 verschiedenen Ziffernblätter AUCH nur Darkmode haben....Ich könnte mir ja einen "hellen" Modus kaufen, aber das ist es mir nicht wert.
Aber dort auch nur, weil sämtlichen anderen 10 verschiedenen Ziffernblätter AUCH nur Darkmode haben....Ich könnte mir ja einen "hellen" Modus kaufen, aber das ist es mir nicht wert.
*Kopfschüttel*
@Musashi, bin komplett bei dir!
Tweaky , ganz im Ernst, ich habe DEINE deutsche Hilfe seit Anbeginn aller AutoIt-Zeiten im Einsatz. Solltest du mal im Rhein-Main-Gebiet sein, melde dich! Eine Einladung in eine Straußwirtschaft/Winzerei mit lecker Essen und Trinken IST DIR SICHER!
In Anlehnung an das Lizenzmodell "Beerware" bin ich eher für "Spätleseware" aber das ist Geschmacksache![]()
![]()