Hallo zusammen!
Ich habe eine Datenbank erstellt, in die ich Textblöcke in unterschiedlichen Sprachen hineinschreiben möchte. Diese "Kopierarbeiten" (Insert) funktionieren wunderbar, so lange keine chinesischen oder russischen Texte geschrieben werden sollen. Diese werden dann als Fragezeichen übertragen.
Nach nun etlichen Stunden des Recherchierens und Probierens gehen mir langsam die Ansätze aus. Außer, dass das Problem etwas mit den Eingestellten/ übertragenen Zeichensätzen zu tun hat (mutmaßlich) hab ich keine Ahnung was ich noch ausprobieren könnte (oder wo das Problem liegt).
Anbei ein Code-Schnipsel, dass die Problematik umschreibt. (Bei Nachhaken gehe ich gerne tiefer)
Local $sUTFcontent[4][1]
$sUTFcontent[0][0] ="Content"
$sUTFcontent[1][0] ="облачные решения для любой отрасли"
$sUTFcontent[2][0] ="業界に特化したモダン"
$sUTFcontent[3][0] ="Loret ipsum äöüß"
_ArrayDisplay($sUTFcontent)
Local $hFileOpen = FileOpen("UTF8.txt", $FO_OVERWRITE)
FileWrite($hFileOpen, $sUTFcontent[1][0])
FileClose($hFileOpen)
_Add2DArrayIntoDB($sUTFcontent, "testcont", $aDBserver) ;Funktion, die das Schreiben (Insert) eines Arrays in eine Tabelle übernimmtIch habe zum Test ein kleines Array angelegt, in dem irgendwelche unterschiedlichen Contents drin sind.
Dann lasse ich mir diese mit _ArrayDisplay anzeigen. -> das Ergebnis ist korrekt
Ich schreibe einen der problematischen Texte in eine Textdatei. -> das Ergebnis ist korrekt
Bis dahin scheint mir klar, dass mit dem Inhalt des Arrays soweit passen dürfte.
Nun kommt es:
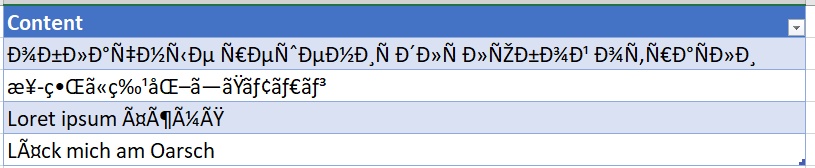
in der Datenbank steht dann folgendes:
Content
----------------------------------
???????? ??????? ??? ????? ???????
??????????
Loret ipsum äöüß
An der kleinen Schreib-Funktion von mir sollte es nicht liegen: Diese schreibt ansonsten alle meine Arrays zu meiner Zufriedenheit in meine Datenbanken ![]()
Also gibt es irgendwo ein Problem mit den verwendeten oder angenommenen Zeichensätzen.
UTF8 als Basis scheint mir geeignet um alle meine Anforderungen abzudecken. Deshalb hab ich schon an den Einstellungen der Datenbank herumgeschraubt. Ein Blick in die Einstellungen der Datenbank:
SHOW VARIABLES LIKE 'character_set\_%'
| character_set_client | utf8 |
| character_set_connection | utf8 |
| character_set_database | utf8 |
| character_set_filesystem | binary |
| character_set_results | utf8 |
| character_set_server | utf8 |
| character_set_system | utf8 |
Wenn ich die Daten mit anderen Programmen (z.B. DBeaver oder aus PhpMyAdmin) in die Datenbank schreibe, dann klappt das alles.
Ergo:
Die Datenbank kann es.
Das Array/Autoit kann es auch (eigentlich)
->irgendwo ist ein Problem beim Übertragen als "UTF8"
Für alle Hinweise dankbar,
Gruß Robbytobi